
Follow infophilosopher:
 |
|

|
|
|
Topics
Introduction
Problems Freedom Knowledge Mind Life Chance Quantum Entanglement Scandals Philosophers Mortimer Adler Rogers Albritton Alexander of Aphrodisias Samuel Alexander William Alston Anaximander G.E.M.Anscombe Anselm Louise Antony Thomas Aquinas Aristotle David Armstrong Harald Atmanspacher Robert Audi Augustine J.L.Austin A.J.Ayer Alexander Bain Mark Balaguer Jeffrey Barrett William Barrett William Belsham Henri Bergson George Berkeley Isaiah Berlin Richard J. Bernstein Bernard Berofsky Robert Bishop Max Black Susan Blackmore Susanne Bobzien Emil du Bois-Reymond Hilary Bok Laurence BonJour George Boole Émile Boutroux Daniel Boyd F.H.Bradley C.D.Broad Michael Burke Jeremy Butterfield Lawrence Cahoone C.A.Campbell Joseph Keim Campbell Rudolf Carnap Carneades Nancy Cartwright Gregg Caruso Ernst Cassirer David Chalmers Roderick Chisholm Chrysippus Cicero Tom Clark Randolph Clarke Samuel Clarke Anthony Collins August Compte Antonella Corradini Diodorus Cronus Jonathan Dancy Donald Davidson Mario De Caro Democritus William Dembski Brendan Dempsey Daniel Dennett Jacques Derrida René Descartes Richard Double Fred Dretske Curt Ducasse John Earman Laura Waddell Ekstrom Epictetus Epicurus Austin Farrer Herbert Feigl Arthur Fine John Martin Fischer Frederic Fitch Owen Flanagan Luciano Floridi Philippa Foot Alfred Fouilleé Harry Frankfurt Richard L. Franklin Bas van Fraassen Michael Frede Gottlob Frege Peter Geach Edmund Gettier Carl Ginet Alvin Goldman Gorgias Nicholas St. John Green Niels Henrik Gregersen H.Paul Grice Ian Hacking Ishtiyaque Haji Stuart Hampshire W.F.R.Hardie Sam Harris William Hasker R.M.Hare Georg W.F. Hegel Martin Heidegger Heraclitus R.E.Hobart Thomas Hobbes David Hodgson Shadsworth Hodgson Baron d'Holbach Ted Honderich Pamela Huby David Hume Ferenc Huoranszki Frank Jackson William James Lord Kames Robert Kane Immanuel Kant Tomis Kapitan Walter Kaufmann Jaegwon Kim William King Hilary Kornblith Christine Korsgaard Saul Kripke Thomas Kuhn Andrea Lavazza James Ladyman Christoph Lehner Keith Lehrer Gottfried Leibniz Jules Lequyer Leucippus Michael Levin Joseph Levine George Henry Lewes C.I.Lewis David Lewis Peter Lipton C. Lloyd Morgan John Locke Michael Lockwood Arthur O. Lovejoy E. Jonathan Lowe John R. Lucas Lucretius Alasdair MacIntyre Ruth Barcan Marcus Tim Maudlin James Martineau Nicholas Maxwell Storrs McCall Hugh McCann Colin McGinn Michael McKenna Brian McLaughlin John McTaggart Paul E. Meehl Uwe Meixner Alfred Mele Trenton Merricks John Stuart Mill Dickinson Miller G.E.Moore Ernest Nagel Thomas Nagel Otto Neurath Friedrich Nietzsche John Norton P.H.Nowell-Smith Robert Nozick William of Ockham Timothy O'Connor Parmenides David F. Pears Charles Sanders Peirce Derk Pereboom Gualtiero Piccinini Steven Pinker U.T.Place Plato Karl Popper Porphyry Huw Price H.A.Prichard Protagoras Hilary Putnam Willard van Orman Quine Frank Ramsey Ayn Rand Michael Rea Thomas Reid Charles Renouvier Nicholas Rescher C.W.Rietdijk Richard Rorty Josiah Royce Bertrand Russell Paul Russell Gilbert Ryle Jean-Paul Sartre Kenneth Sayre T.M.Scanlon Moritz Schlick John Duns Scotus Albert Schweitzer Arthur Schopenhauer John Searle Wilfrid Sellars David Shiang Alan Sidelle Ted Sider Henry Sidgwick Walter Sinnott-Armstrong Peter Slezak J.J.C.Smart Saul Smilansky Michael Smith Baruch Spinoza L. Susan Stebbing Isabelle Stengers George F. Stout Galen Strawson Peter Strawson Eleonore Stump Francisco Suárez Richard Taylor Kevin Timpe Mark Twain Peter Unger Peter van Inwagen Manuel Vargas John Venn Kadri Vihvelin Voltaire G.H. von Wright David Foster Wallace R. Jay Wallace W.G.Ward Ted Warfield Roy Weatherford C.F. von Weizsäcker William Whewell Alfred North Whitehead David Widerker David Wiggins Bernard Williams Timothy Williamson Ludwig Wittgenstein Susan Wolf Xenophon Scientists David Albert Philip W. Anderson Michael Arbib Bobby Azarian Walter Baade Bernard Baars Jeffrey Bada Leslie Ballentine Marcello Barbieri Jacob Barandes Julian Barbour Horace Barlow Gregory Bateson Jakob Bekenstein John S. Bell Mara Beller Charles Bennett Ludwig von Bertalanffy Susan Blackmore Margaret Boden David Bohm Niels Bohr Ludwig Boltzmann John Tyler Bonner Emile Borel Max Born Satyendra Nath Bose Walther Bothe Jean Bricmont Hans Briegel Leon Brillouin Daniel Brooks Stephen Brush Henry Thomas Buckle S. H. Burbury Melvin Calvin William Calvin Donald Campbell John O. Campbell Sadi Carnot Sean B. Carroll Anthony Cashmore Eric Chaisson Gregory Chaitin Jean-Pierre Changeux Rudolf Clausius Arthur Holly Compton John Conway Simon Conway-Morris Peter Corning George Cowan Jerry Coyne John Cramer Francis Crick E. P. Culverwell Antonio Damasio Olivier Darrigol Charles Darwin Paul Davies Richard Dawkins Terrence Deacon Lüder Deecke Richard Dedekind Louis de Broglie Stanislas Dehaene Max Delbrück Abraham de Moivre David Depew Bernard d'Espagnat Paul Dirac Theodosius Dobzhansky Hans Driesch John Dupré John Eccles Arthur Stanley Eddington Gerald Edelman Paul Ehrenfest Manfred Eigen Albert Einstein George F. R. Ellis Walter Elsasser Hugh Everett, III Franz Exner Richard Feynman R. A. Fisher David Foster Joseph Fourier George Fox Philipp Frank Steven Frautschi Edward Fredkin Augustin-Jean Fresnel Karl Friston Benjamin Gal-Or Howard Gardner Lila Gatlin Michael Gazzaniga Nicholas Georgescu-Roegen GianCarlo Ghirardi J. Willard Gibbs James J. Gibson Nicolas Gisin Paul Glimcher Thomas Gold A. O. Gomes Brian Goodwin Julian Gough Joshua Greene Dirk ter Haar Jacques Hadamard Mark Hadley Ernst Haeckel Patrick Haggard J. B. S. Haldane Stuart Hameroff Augustin Hamon Sam Harris Ralph Hartley Hyman Hartman Jeff Hawkins John-Dylan Haynes Donald Hebb Martin Heisenberg Werner Heisenberg Hermann von Helmholtz Grete Hermann John Herschel Francis Heylighen Basil Hiley Art Hobson Jesper Hoffmeyer John Holland Don Howard John H. Jackson Ray Jackendoff Roman Jakobson E. T. Jaynes William Stanley Jevons Pascual Jordan Eric Kandel Ruth E. Kastner Stuart Kauffman Martin J. Klein William R. Klemm Christof Koch Simon Kochen Hans Kornhuber Stephen Kosslyn Daniel Koshland Ladislav Kovàč Leopold Kronecker Bernd-Olaf Küppers Rolf Landauer Alfred Landé Pierre-Simon Laplace Karl Lashley David Layzer Joseph LeDoux Gerald Lettvin Michael Levin Gilbert Lewis Benjamin Libet David Lindley Seth Lloyd Werner Loewenstein Hendrik Lorentz Josef Loschmidt Alfred Lotka Ernst Mach Donald MacKay Henry Margenau Lynn Margulis Owen Maroney David Marr Humberto Maturana James Clerk Maxwell John Maynard Smith Ernst Mayr John McCarthy Barbara McClintock Warren McCulloch N. David Mermin George Miller Stanley Miller Ulrich Mohrhoff Jacques Monod Vernon Mountcastle Gerd B. Müller Emmy Noether Denis Noble Donald Norman Travis Norsen Howard T. Odum Alexander Oparin Abraham Pais Howard Pattee Wolfgang Pauli Massimo Pauri Wilder Penfield Roger Penrose Massimo Pigliucci Steven Pinker Colin Pittendrigh Walter Pitts Max Planck Susan Pockett Henri Poincaré Michael Polanyi Daniel Pollen Ilya Prigogine Hans Primas Giulio Prisco Zenon Pylyshyn Henry Quastler Adolphe Quételet Pasco Rakic Nicolas Rashevsky Lord Rayleigh Frederick Reif Jürgen Renn Giacomo Rizzolati A.A. Roback Emil Roduner Juan Roederer Robert Rosen Frank Rosenblatt Jerome Rothstein David Ruelle David Rumelhart Michael Ruse Stanley Salthe Robert Sapolsky Tilman Sauer Ferdinand de Saussure Jürgen Schmidhuber Erwin Schrödinger Aaron Schurger Sebastian Seung Thomas Sebeok Franco Selleri Claude Shannon James A. Shapiro Charles Sherrington Abner Shimony Herbert Simon Dean Keith Simonton Edmund Sinnott B. F. Skinner Lee Smolin Ray Solomonoff Herbert Spencer Roger Sperry John Stachel Kenneth Stanley Henry Stapp Ian Stewart Tom Stonier Antoine Suarez Leonard Susskind Leo Szilard Max Tegmark Teilhard de Chardin Libb Thims William Thomson (Kelvin) Richard Tolman Giulio Tononi Peter Tse Alan Turing Robert Ulanowicz C. S. Unnikrishnan Nico van Kampen Francisco Varela Vlatko Vedral Vladimir Vernadsky Clément Vidal Mikhail Volkenstein Heinz von Foerster Richard von Mises John von Neumann Jakob von Uexküll C. H. Waddington Sara Imari Walker James D. Watson John B. Watson Daniel Wegner Steven Weinberg August Weismann Paul A. Weiss Herman Weyl John Wheeler Jeffrey Wicken Wilhelm Wien Norbert Wiener Eugene Wigner E. O. Wiley E. O. Wilson Günther Witzany Carl Woese Stephen Wolfram H. Dieter Zeh Semir Zeki Ernst Zermelo Wojciech Zurek Konrad Zuse Fritz Zwicky Presentations ABCD Harvard (ppt) Bhaktivedanta Aug 2026 Biosemiotics Free Will Mental Causation James Symposium CCS25 Talk Evo Devo September 12 Evo Devo October 2 Evo Devo Davies Nov12 |
Rolf Landauer
Rolf Landauer extended the ideas of John von Neumann and Leo Szilard, who, along with many other physicists, had connected a physical measurement with thermodynamical irreversibility, that is to say a dissipation of available (free) energy and an increase in entropy.
The increase in entropy (or decrease in available negentropy, as Leon Brillouin put it), must equal or exceed the increase in information acquired in the measurement, in order to satisfy the second law of thermodynamics.
In 1961 Landauer published a landmark article in the IBM Journal. He studied the special case of digital computers which read and write information as part of their calculations, but have extremely small or possibly even zero energy dissipation, especially in computations that are in principle logically reversible. Such calculations must include their input values along with their outputs, in order to allow the computer to step backward through the calculation and restore the original state.
Landauer's thinking assumes physics is completely deterministic. In classical mechanics trajectories are a known function of the forces and initial conditions. Complete knowledge of those conditions implies knowledge of the conditions at all times, past and future.
Since the system is conservative, its whole history can be reversed in time, and we will still have a system satisfying the laws of motion. In the time-reversed system we then have the possibility that for a single initial condition (position in the one state, zero velocity) we can end up in at least two places: the zero state or the one state. This, however, is impossible. The laws of mechanics are completely deterministic and a trajectory is determined by an initial position and velocity. (Landauer argues that the most fundamental laws of physics are time reversible. Complete knowledge of the state of a closed system at some time, you could - in principle—run the laws of physics in reverse and determine the system’s exact state at any previous time. This can be approximated by large classical objects such as billiard balls (cf., the "digital physics" of Ed Fredkin). This is of course an idealization not realizable in the quantum world. The idea of logical reversibility can not be realized in a world that is physically irreversible. Since the introduction of quantum mechanics and the realization that we live in a universe with irreducible background noise (the cosmic microwave background radiation with a temperature of about 3°K), noise and entropy-free deterministic systems are the idealizations of mathematicians, philosophers, and computer scientists. Indeed, a major difference between Bell Labs and IBM can perhaps be seen in the observation that Bell Labs has learned to communicate signals in the presence of noise and discovered the ultimate cosmic source of entropic noise, where IBM has excelled at eliminating the effects of noise from our best computers. At Bell Labs, Claude Shannon developed information theory, with its fundamental connection to Ludwig Boltzmann's entropy. And there Arno Penzias and Robert Wilson discovered the cosmic background radiation. At IBM, Landauer and his colleague Charles Bennett are famous for logically and thermodynamically reversible computing, which ignores the effects of noise and entropy until the computer bits of information must be erased (Landauer's Principle).
Note that Landauer's work is mostly logical and does not discuss the underlying physics of irreversibility.
Logically irreversible devices do not remember the inputs. They are thus one-way processes that lose information. Logically irreversible devices are necessary to computing, says Landauer, and logical irreversibility implies physical irreversibility.
We shall call a device logically irreversible if the output of a device does not uniquely define the inputs. We believe that devices exhibiting logical irreversibility are essential to computing. Logical irreversibility, we believe, in turn implies physical irreversibility, and the latter is accompanied by dissipative effects.Landauer then goes on to describe classes of computers that can be considered logically reversible. They must not only save their inputs, but also the results of all intermediate logical steps, to provide the necessary information to perform all the steps backwards and restore the original conditions. In particular, he says, no information can be erased. That the entropy must go up on erasure is known as Landauer's Principle. Landauer's colleague at IBM, Charles Bennett, carries on the investigations of logically reversible computing. Landauer describes two examples of logically reversible machines. [The first is] a particular class of computers, namely those using logical functions of only one or two variables. After a machine cycle each of our N binary elements is a function of the state of at most two of the binary elements before the machine cycle. Now assume that the computer is logically reversible. Then the machine cycle maps the 2N possible initial states of the machine onto the same space of 2N states, rather than just a subspace thereof. In the 2N possible states each bit has a ONE and a ZERO appearing with equal frequency. Hence the reversible computer can utilize only those truth functions whose truth table exhibits equal numbers of ONES and ZEROS. The admissible truth functions then are the identity and negation, the EXCLUSIVE OR and its negation. These, however, are not a complete set' and do not permit a synthesis of all other truth functions. [Landauer also describes] more general devices. Consider, for example, a particular three-input, three-output device, i.e., a small special purpose computer with three bit positions. Let p, q, and r be the variables before the machine cycle. The particular truth function under consideration is the one which replaces r by p • q if r = 0, and replaces r by NOT p • q if r = 1. The variables p and q are left unchanged during the machine cycle. We can consider r as giving us a choice of program, and p, q as the variables on which the selected program operates. This is a logically reversible device, its output always defines its input uniquely. Nevertheless it is capable of performing an operation such as AND which is not, in itself, reversible. The computer, however, saves enough of the input information so that it supplements the desired result to allow reversibility. It is interesting to note, however, that we did not "save" the program; we can only deduce what it was. Now consider a more general purpose computer, which usually has to go through many machine cycles to carry out a program. At first sight it may seem that logical reversibility is simply obtained by saving the input in some corner of the machine. We shall, however, label a machine as being logically reversible, if and only if all its individual steps are logically reversible. This means that every single time a truth function of two variables is evaluated we must save some additional information about the quantities being operated on, whether we need it or not. Erasure, which is equivalent to RESTORE TO ONE. discussed in the Introduction, is not permitted. We will, therefore, in a long program clutter up our machine bit positions with unnecessary information about intermediate results. Furthermore if we wish to use the reversible function of three variables, which was just discussed. as an AND, then we must supply in the initial programming a separate ZERO for every AND operation which is subsequently required, since the "bias" which programs the device is not saved, when the AND is performed. The machine must therefore have a great deal of extra capacity to store both the extra "bias" bits and the extra outputs. Can it be given adequate capacity to make all intermediate steps reversible? If our machine is capable, as machines are generally understood to be, of a non-terminating program, then it is clear that the capacity for preserving all the information about all the intermediate steps cannot be there. Let us, however, not take such an easy way out. Perhaps it is just possible to devise a machine, useful in the normal sense, but not capable of embarking on a nonterminating program. Let us take such a machine as it normally comes, involving logically irreversible truth functions. An irreversible truth function can be made into a reversible one, as we have illustrated, by "embedding" it in a truth function of a large number of variables. The larger truth function, however, requires extra inputs to bias it, and extra outputs to hold the information which provides the reversibility. What we now contend is that this larger machine, while it is reversible, is not a useful computing machine in the normally accepted sense of the word. First of all, in order to provide space for the extra inputs and outputs, the embedding requires knowledge of the number of times each of the operations of the original (irreversible) machine will be required. The usefulness of a computer stems, however, from the fact that it is more than just a table look-up device; it can do many programs which were not anticipated in full detail by the designer. Our enlarged machine must have a number of bit positions, for every embedded device of the order of the number of program steps and requires a number of switching events during program loading comparable to the number that occur during the program itself. The setting of bias during program loading, which would typically consist of restoring a long row of bits to say ZERO, is just the type of nonreversible logical operation we are trying to avoid. Our unwieldy machine has therefore avoided the irreversible operations during the running of the program, only at the expense of added comparable irreversibility during the loading of the program. For Teachers
For Scholars
The Future of Computing Depends on Making It Reversible
It’s time to embrace reversible computing, which could offer dramatic improvements in energy efficiency By Michael P. Frank For more than 50 years, computers have made steady and dramatic improvements, all thanks to Moore’s Law—the exponential increase over time in the number of transistors that can be fabricated on an integrated circuit of a given size. Moore’s Law owed its success to the fact that as transistors were made smaller, they became simultaneously cheaper, faster, and more energy efficient. The payoff from this win-win-win scenario enabled reinvestment in semiconductor fabrication technology that could make even smaller, more densely packed transistors. And so this virtuous circle continued, decade after decade. Now though, experts in industry, academia, and government laboratories anticipate that semiconductor miniaturization won’t continue much longer—maybe 5 or 10 years. Making transistors smaller no longer yields the improvements it used to. The physical characteristics of small transistors caused clock speeds to stagnate more than a decade ago, which drove the industry to start building chips with multiple cores. But even multicore architectures must contend with increasing amounts of “dark silicon,” areas of the chip that must be powered off to avoid overheating. Heroic efforts are being made within the semiconductor industry to try to keep miniaturization going. But no amount of investment can change the laws of physics. At some point—now not very far away—a new computer that simply has smaller transistors will no longer be any cheaper, faster, or more energy efficient than its predecessors. At that point, the progress of conventional semiconductor technology will stop. What about unconventional semiconductor technology, such as carbon-nanotube transistors, tunneling transistors, or spintronic devices? Unfortunately, many of the same fundamental physical barriers that prevent today’s complementary metal-oxide-semiconductor (CMOS) technology from advancing very much further will still apply, in a modified form, to those devices. We might be able to eke out a few more years of progress, but if we want to keep moving forward decades down the line, new devices are not enough: We’ll also have to rethink our most fundamental notions of computation. Let me explain. For the entire history of computing, our calculating machines have operated in a way that causes the intentional loss of some information (it’s destructively overwritten) in the process of performing computations. But for several decades now, we have known that it’s possible in principle to carry out any desired computation without losing information—that is, in such a way that the computation could always be reversed to recover its earlier state. This idea of reversible computing goes to the very heart of thermodynamics and information theory, and indeed it is the only possible way within the laws of physics that we might be able to keep improving the cost and energy efficiency of general-purpose computing far into the future. In the past, reversible computing never received much attention. That’s because it’s very hard to implement, and there was little reason to pursue this great challenge so long as conventional technology kept advancing. But with the end now in sight, it’s time for the world’s best physics and engineering minds to commence an all-out effort to bring reversible computing to practical fruition. The history of reversible computing begins with physicist Rolf Landauer of IBM, who published a paper in 1961 titled “Irreversibility and Heat Generation in the Computing Process.” In it, Landauer argued that the logically irreversible character of conventional computational operations has direct implications for the thermodynamic behavior of a device that is carrying out those operations. Landauer’s reasoning can be understood by observing that the most fundamental laws of physics are reversible, meaning that if you had complete knowledge of the state of a closed system at some time, you could always—at least in principle—run the laws of physics in reverse and determine the system’s exact state at any previous time. To better see that, consider a game of billiards—an ideal one with no friction. If you were to make a movie of the balls bouncing off one another and the bumpers, the movie would look normal whether you ran it backward or forward: The collision physics would be the same, and you could work out the future configuration of the balls from their past configuration or vice versa equally easily. The same fundamental reversibility holds for quantum-scale physics. As a consequence, you can’t have a situation in which two different detailed states of any physical system evolve into the exact same state at some later time, because that would make it impossible to determine the earlier state from the later one. In other words, at the lowest level in physics, information cannot be destroyed. The reversibility of physics means that we can never truly erase information in a computer. Whenever we overwrite a bit of information with a new value, the previous information may be lost for all practical purposes, but it hasn’t really been physically destroyed. Instead it has been pushed out into the machine’s thermal environment, where it becomes entropy—in essence, randomized information—and manifests as heat. Returning to our billiards-game example, suppose that the balls, bumpers, and felt were not frictionless. Then, sure, two different initial configurations might end up in the same state—say, with the balls resting on one side. The frictional loss of information would then generate heat, albeit a tiny amount. Today’s computers rely on erasing information all the time—so much so that every single active logic gate in conventional designs destructively overwrites its previous output on every clock cycle, wasting the associated energy. A conventional computer is, essentially, an expensive electric heater that happens to perform a small amount of computation as a side effect. Back to the Future Reversible computing is based on reversible physics, where no energy is lost to friction 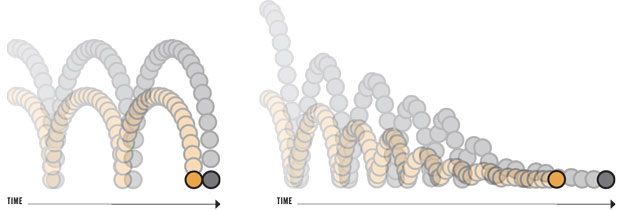
Illustration: James Provost TWO IDEAL BALLS, perfectly elastic and free of internal friction, are dropped from different heights. They will then bounce back repeatedly to their original heights. At any point, the future or past velocity and position of a ball can be calculated based on its current velocity and position [left]. But if there is internal friction, the situation is no longer reversible: Both balls ultimately end up on the ground, and you cannot determine their past velocities and positions from their current ones [right]. Here, energy is wasted through the frictional generation of heat. 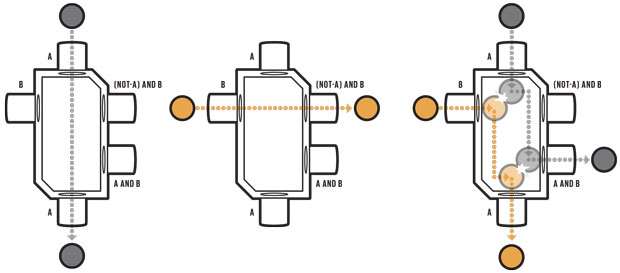
Illustration: James Provost A LOGIC GATE could, in principle, be constructed from idealized balls and barriers. This billiard-ball AND gate has two inputs and three outputs. If a “true” is applied only to the “A” input (a ball entering from the top), then a “true” will appear on the “A” output (ball exiting from the bottom) [left]. If “true” is applied only to the “B” input (a ball entering from the left), then a “true” will appear only on the “(NOT-A) AND B” output (ball exiting to the right) [middle]. If “true” is applied to both inputs, then a “true” will appear on both the “A” and “A AND B” outputs [right]. How much heat is produced? Landauer’s conclusion, which has since been experimentally confirmed, was that each bit erasure must dissipate at least 17-thousandths of an electron volt at room temperature. This is a very small amount of energy, but given all the operations that take place in a computer, it adds up. Present-day CMOS technology actually does much worse than Landauer calculated, dissipating something in the neighborhood of 5,000 electron volts per bit erased. Standard CMOS designs could be improved in this regard, but they won’t ever be able to get much below about 500 eV of energy lost per bit erased, still far from Landauer’s lower limit. Can we do better? Landauer began to consider this question in his 1961 paper where he gave examples of logically reversible operations, meaning ones that transform computational states in such a way that each possible initial state yields some unique final state. Such operations could, in principle, be carried out in a thermodynamically reversible way, in which case any energy associated with the information-bearing signals in the system would not necessarily have to be dissipated as heat but could instead potentially be reused for subsequent operations. To prove this approach could still do everything a conventional computer could do, Landauer also noted that any desired logically irreversible computational operation could be embedded in a reversible one, by simply setting aside any information that was no longer needed, rather than erasing it. But Landauer originally thought that doing this was only delaying the inevitable, because the information would still need to be erased eventually, when the available memory filled up. It was left to Landauer’s younger colleague, Charles Bennett, to show in 1973 that it is possible to construct fully reversible computers capable of performing any computation without quickly filling up memory with temporary data. The trick is to undo the operations that produced the intermediate results. This would allow any temporary memory to be reused for subsequent computations without ever having to erase or overwrite it. In this way, reversible computations, if implemented on the right hardware, could, in principle, circumvent Landauer’s limit. Unfortunately, Bennett’s idea of using reversible computing to make computation far more energy efficient languished in academic backwaters for many years. The problem was that it’s really hard to engineer a system that does something computationally interesting without inadvertently incurring a significant amount of entropy increase with each operation. But technology has improved, and the need to minimize energy use is now acute. So some researchers are once again looking to reversible computing to save energy. What would a reversible computer look like? The first detailed attempts to describe an efficient physical mechanism for reversible computing were carried out in the late 1970s and early 1980s by Edward Fredkin and his colleague Tommaso Toffoli in their Information Mechanics research group at MIT. As a proof of concept, Fredkin and Toffoli proposed that reversible operations could, in principle, be carried out by idealized electronic circuits that used inductors to shuttle charge packets back and forth between capacitors. With no resistors damping the flow of energy, these circuits were theoretically lossless. In the mechanical domain, Fredkin and Toffoli imagined rigid spheres bouncing off of each other and fixed barriers in narrowly constrained trajectories, not unlike the frictionless billiards game I described earlier. Unfortunately, these idealized systems couldn’t be built in practice. But these investigations led to the development of two abstract computational primitives, now known as the Fredkin gate and the Toffoli gate, which became the foundation of much of the subsequent theoretical work in reversible computing. Any computation can be performed using these gates, which operate on three input bits, transforming them into unique final configurations of three output bits. Meanwhile, other researchers at such places as Caltech, Rutgers, the University of Southern California, and Xerox PARC continued to explore possible electronic implementations. They called their circuits “adiabatic” after the idealized thermodynamic regime in which energy is barred from leaving the system as heat. These ideas later found fertile ground back at MIT, where in 1993 a graduate student named Saed Younis in Tom Knight’s group showed for the first time that adiabatic circuits could be used to implement fully reversible logic. Later students in the group, including Carlin Vieri and I, built on that foundation to design and construct fully reversible processors of various types in CMOS as simple proofs of concept. This work established that there were no fundamental barriers preventing the entire discipline of computer architecture from being translated to the reversible realm. Meanwhile, other researchers had been exploring alternative approaches to implementing reversible computing that were not based on semiconductor electronics at all. In the early 1990s, nanotechnology visionary K. Eric Drexler produced detailed designs for reversible nanomechanical logic devices made from diamond-like materials. Over the decades, Russian and Japanese researchers had been developing reversible superconducting electronic devices, such as the similarly named (but distinct) parametric quantron and quantum flux parametron. And a group at the University of Notre Dame was studying how to use interacting single electrons in arrays of quantum dots. To those of us who were working on reversible computing in the 1990s, it seemed that, based on the wide range of possible hardware that had already been proposed, some kind of practical reversible computing technology might not be very far away. Alas, the idea was still ahead of its time. Conventional semiconductor technology improved rapidly through the 1990s and early 2000s, and so the field of reversible computing mostly languished. Nevertheless, some progress was made. For example, in 2004 Krishna Natarajan (a student I was advising at the University of Florida) and I showed in detailed simulations that a new and simplified family of circuits for reversible computing called two-level adiabatic logic, or 2LAL, could dissipate as little as 1 eV of energy per transistor per cycle—about 0.001 percent of the energy normally used by logic signals in that generation of CMOS. Still, a practical reversible computer has yet to be built using this or other approaches. There’s not much time left to develop reversible machines, because progress in conventional semiconductor technology could grind to a halt soon. And if it does, the industry could stagnate, making forward progress that much more difficult. So the time is indeed ripe now to pursue this technology, as it will probably take at least a decade for reversible computers to become practical. The most crucial need is for new reversible device technologies. Conventional CMOS transistors—especially the smallest, state-of-the-art ones—leak too much current to make very efficient adiabatic circuits. Larger transistors based on older manufacturing technology leak less, but they’d have to be operated quite slowly, which means many devices would need to be used to speed up computation through parallel operation. Stacking them in layers could yield compact and energy-efficient adiabatic circuits, but at the moment such 3D fabrication is still quite costly. And CMOS may be a dead end in any case. Computing With Tiny Link Logic 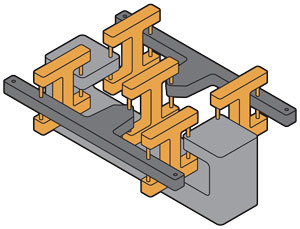
Illustration: James Provost Ralph Merkle and his colleagues envision doing computations using nanomechanical “link logic,” a building block for which is shown here. That device contains two movable bars [dark gray], connected in such a way that only one bar at a time can be shifted from its central position. These bars would measure a few hundred atoms across, and their pivot points would be nearly frictionless. So great numbers of them connected together in the proper fashion could perform calculations, just as transistors do today. The difference is that a tiny link-logic system would be reversible. Fortunately, there are some promising alternatives. One is to use fast superconducting electronics to build reversible circuits, which have already been shown to dissipate less energy per device than the Landauer limit when operated reversibly. Advances in this realm have been made by researchers at Yokohama National University, Stony Brook University, and Northrop Grumman. Meanwhile, a team led by Ralph Merkle at the Institute for Molecular Manufacturing in Palo Alto, Calif., has designed reversible nanometer-scale molecular machines, which in theory could consume one-hundred-billionth the energy of today’s computing technology while still switching on nanosecond timescales. The rub is that the technology to manufacture such atomically precise devices still needs to be invented. Whether or not these particular approaches pan out, physicists who are working on developing new device concepts need to keep the goal of reversible operation in mind. After all, that is the only way that any new computing substrate can possibly surpass the practical capabilities of end-of-line CMOS technology by many orders of magnitude, as opposed to only a few at most. To be clear, reversible computing is by no means easy. Indeed, the engineering hurdles are enormous. Achieving efficient reversible computing with any kind of technology will likely require a thorough overhaul of our entire chip-design infrastructure. We’ll also have to retrain a large part of the digital-engineering workforce to use the new design methodologies. I would guess that the total cost of all of the new investments in education, research, and development that will be required in the coming decades will most likely run well up into the billions of dollars. It’s a future-computing moon shot. But in my opinion, the difficulty of these challenges would be a very poor excuse for not facing up to them. At this moment, we’ve arrived at a historic juncture in the evolution of computing technology, and we must choose a path soon. If we continue on our present course, this would amount to giving up on the future of computing and accepting that the energy efficiency of our hardware will soon plateau. Even such unconventional concepts as analog or spike-based neural computing will eventually reach a limit if they are not designed to also be reversible. And even a quantum-computing breakthrough would only help to significantly speed up a few highly specialized classes of computations, not computing in general. But if we decide to blaze this new trail of reversible computing, we may continue to find ways to keep improving computation far into the future. Physics knows no upper limit on the amount of reversible computation that can be performed using a fixed amount of energy. So as far as we know, an unbounded future for computing awaits us, if we are bold enough to seize it. This article appears in the September 2017 print issue as “Throwing Computing Into Reverse.” About the Author Michael P. Frank is a senior member of the technical staff at Sandia National Laboratories, in Albuquerque, where he studies advanced technologies for computation.
|



